Solving the Vertex-Weighted Steiner Tree Problem
Bachelor/Semester
| Steiner Tree problems are amongst the hot spots of modern research in the field of discrete optimization and have wide ranging applications. In this semester project we will first consider the classic Steiner Tree Problem: Given an undirected graph with a weight function on the edges and a set of terminal vertices, find a minimum weight tree that connects all the terminals. We will then consider the problem where the weight function is given on the vertices (instead of on the edges) and the task is to select a minimum weight set of vertices that connects the terminals. This is the so-called vertex-weighted Steiner Tree Problem. |
 |
There are known algorithms for the Steiner Tree problem that solve practical instances efficiently. However, little is known about the vertex-weighted problem. The ultimate goal of this project is to develop, implement and analyze algorithms that solve the vertex-weighted Steiner Tree problem.
Objective
- Literature review on algorithms for Steiner Tree (e.g. Dreyfus and Wagner: “The Steiner Problem in Graphs”, Networks, 1, p. 195-207, 1972)
- Implementation and benchmarking of algorithms for Steiner Tree
- Development of algorithms for vertex-weighted Steiner Tree
- Implementation, benchmarking, and theoretical analysis of the running time of these algorithms.
Contact person
Solving the Assignment and Timetabling problem
Semester
This project is a collaboration with the canton de Vaud. It deals with the scheduling of school classes (teachers, students and rooms). The project consists of
o Defining the partitioning and scheduling problem mathematically
o Finding an integer programming model
o Solving the integer program (Heuristics and cutting planes)
Large parts of the time will be devoted to interacting with the corresponding spokesperson of the schools at the Canton de Vaud.
Prerequisites: Course on Discrete Optimization and basic knowledge of integer programming
Literature: Arabinda Tripathy: School Timetabling – a case in large binary integer linear programming. Management Science, 1984.
Contact person:
Message decoding using linear programming
Semester
In a classical setting in coding theory there is a party, say Alice, that wants to send a *message* x ∈ R^n to a second party, say Bob. For security reasons, Alice encrypts the message via a (full column rank) matrix A ∈ R^m×n (with m > n); that is, Alice is going to send Ax to Bob. Unfortunately, the transmission channel is disturbed, hence Bob is going to receive the message y = Ax + z , where z ∈ R^m is the *noise* of the channel, and does not depend on the specific message x. Hence, Bob has to face the following problem: given A and y, can he reconstruct x?
It can be showed that if the *support* of the noise z (that is, the number of its non-zero components) is small with respect to m, then, with probability almost 1, z is the optimal solution to an appropriate linear program. Hence, with very high probability, Bob can reconstruct z (and therefore the message x) in polynomial time. This result is based on important tools from discrete geometry and has also applications in compressed sensing, that is a technique used to reconstruct sparse signals. The goal of this project is to understand those theoretical results, test their performance on some real data, and try to extend them to related problems.
Contact person:
Solving Boolean Satisfiability Problems
Master/Bachelor/Semester
A boolean formula is any combination of boolean variables using boolean operators and, or, and not, such as (x ∨ ¬y) ∧ (¬x ∨ y ∨ z). The satisfiability problem asks us to find an assignment of truth values (true or false) to the variables that makes a given boolean formula true, or assert that no such assignment exists. As an example, the formula x ∧ ¬x is trivially unsatisfiable, because the formula is false no matter how the variable x is assigned.
Boolean Satisfiability is one of the most fundamental NP-hard problems. Its importance comes from the numerous industrial problems that can be easily formulated as satisfiability problems. To solve such problems in practice, they are typically converted to Conjunctive normal form (CNF) and then solved using extensions of the DPLL algorithm.
Objectives
The ultimate objective of this project is to extend an existing, basic DPLL solver with modern techniques and features. There are a number of possible directions to choose from:
- Heuristics for branching decisions: During the search for a satisfying assignment, the solver typically has to “make guesses” at some point. In other words, it will decide to fix one variable arbitrarily and then later backtrack if necessary. Heuristics are concerned with trying to make “good” choices most of the time.
- Clause learning: When the solver runs into a dead end in its search, it can often “learn” that a certain small assignment of variables cannot happen together. This “learning” is done by analyzing the graph of implications that were found by the solver, and a new clause is added to the problem to represent the newly learned fact.
- Preprocessing techniques: Satisfiability instances are usually generated automatically, often without concern for the particular solver used as a backend. Therefore, preprocessing techniques such as subsumed and self-subsumed clauses may be used to reduce the size of the instance before the main part of the solver runs.
- Extracting unsatisfiable cores: When a boolean formula in CNF is unsatisfiable, it may be of interest to find a small subset of the clauses that is already unsatisfiable by itself. Ideally, this unsatisfiable core may serve as the basis for a relatively short proof of unsatisfiability.
In each case, the project consists of three parts:
- Literature review: Create an overview of publications in the area to learn how existing solvers implement the techniques in question.
- Implementation and benchmarking: Add the technique to a basic solver and test its effectiveness on a range of benchmarking instances.
- Open-ended Research: Using the lessons learned from the first two parts, formulate extensions or variants of the existing techniques, and compare their effectiveness to those found in the literature.
Contact person
Computing real roots of multivariate polynomials
Semester
Computing the real roots of polynomials is a problem of wide theoretical and practical interest. In the case of univariate polynomials, Sturm’s theorem provides a very elegant answer to this problem, but this method is unapplicable to the case of multivariate polynomials. Nevertheless, a consequence of the Tarski-Seidenberg theorem is that the problem of finding whether a multivariate polynomial has real roots is decidable.
Objective
The goal of this project is to understand the Tarski-Seidenberg theorem, and to implement the decision algorithm in the case of two variables polynomials, as described in the article “New Decision Method for Elementary Algebra”, by A. Seidenberg. The algorithm will preferably be implemented using a computer algebra system, such as Sage. If time permits, a further goal would be to implement some root localization algorithms for multivariate polynomials.
Contact person
Metaheuristics for the ring loading problem
Semester
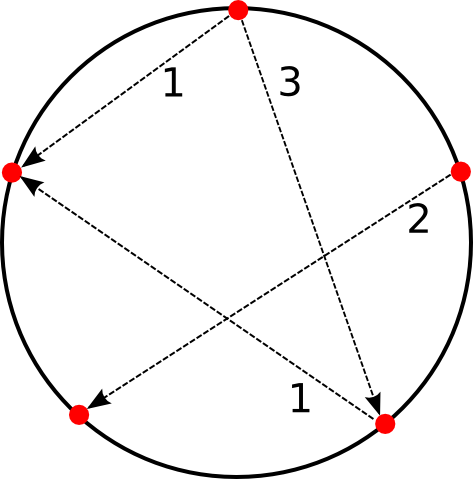
In a SONET ring, a set of nodes (typically telephone central offices) are connected by a ring of optical fiber.
These nodes want to exchange data simultaneously. If node i sends data to node j of size di,j, it has two choices: It can send the data the clockwise direction or the anticlockwise direction on the circle. Either way generates a load of di,j on the edges of the ring used for the routing.
 |
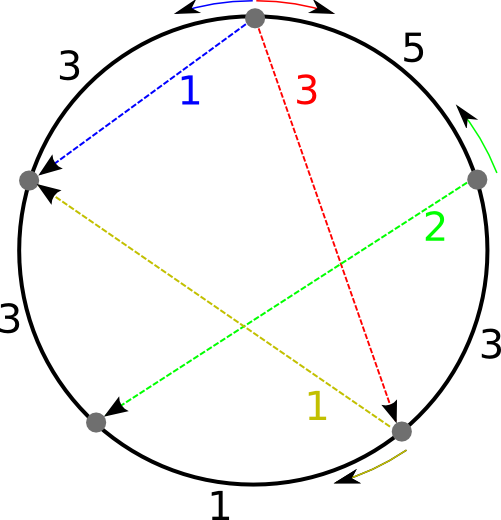 |
The sum of the loads generated for an edge give a lower bound on the capacity of the edge. The higher the required capacity, the more expensive the sonet ring is. Since SONET rings are symmetric, i.e. each edge has the same capacity, minimizing the cost of the sonet ring means to find a routing that minimizes the maximal capacity needed for the edges.
This problem is NP-hard, but there is an approximation algorithm by Schrijver, Seymour and Winkler that achieves a solution no worse than the optimum plus 3/2 times the maximum of the di,j.
The algorithm computes a “fractional” solution to the problem, where one is allowed to send an arbitrary fraction of the data in both the clockwise and anticlockwise direction. In a second step it uses a greedy type algorithm to round this to a solution that does not split the traffic.
It is an open problem if the approximation algorithm can be improved by replacing the greedy algorithm in the second step by more sophisticated approaches. This boils down to the following problem:
Find the minimum α such that for all positive integers m and nonnegative reals u1,.. , um, v1, …, vm with ui+vi ≤ 1 there exists reals z1, …, zm such that for each k=1,…,m:
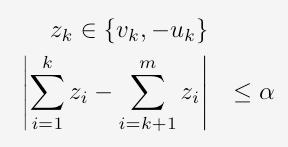
It is known that 1 < α ≤ 3/2. Your goal is to improve the lower bound for α by finding a “bad instance”, i.e. ui and vi that enforces an α significantly larger than 1.
The suggested way of doing this is to apply metaheuristics such as the Monte Carlo method, simulated annealing or genetic algorithms. Basic knowledge of C++ or Java is appreciated.
Contact person:
Semester
Warehouse Location
Our industrial partner would like to compute optimal location for their warehouses in Switzerland. The aim of this project is to understand the underlying optimization problem, try to solve it with the existing techniques (e.g. IP-solvers, approximation algorithms, heuristics), and possibly to develop techniques dedicated to the particular setting.
With some simplification the problem is as follows. Given location of factories with their production capacities and the location of clients with their demands (based on data from the year 2009), we seek to find good location of a few warehouses which minimizes the total transportation cost. For simplicity we assume there is only a single product distributed (single commodity transshipment problem).
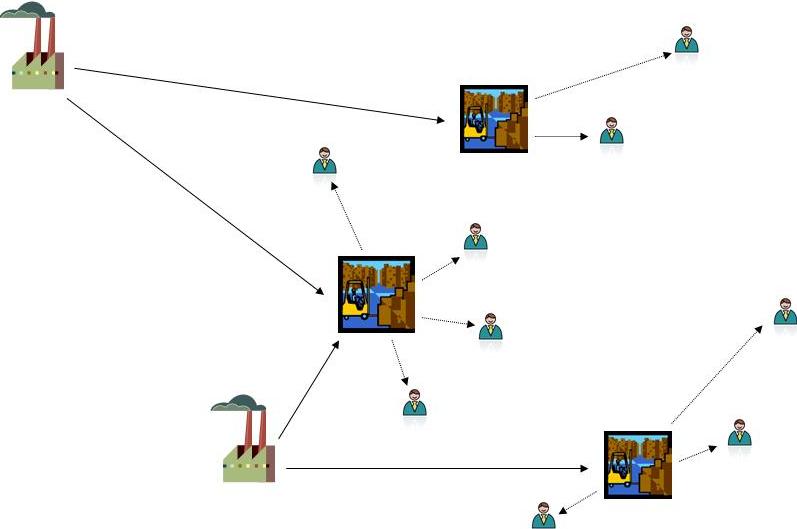
Since transporting in higher quantities is generally cheaper (per unit), intuitively, warehouses should be built close to gravity centers of the groups of clients they serve. Depending on the structure of the cost function and additional constraints (like capacities of warehouses) one obtains different types of location problems.
An important part of this project is to understand the actual problem that needs to be solved. At this stage it is essential to work in a collaboration with the industrial partner.
The next stage would be to model the problem as an integer program and to collect all the necessary data (like pairwise distances between a number of locations in Switzerland)
Then one should apply various techniques in an attempt to (approximately) solve the obtained mathematical problem and to report the findings to both scientist at EPFL and the industrial partner.
The project has a potential theoretical extension. The above described problem is closely related to, but not equivalent to any of the extensively studied location problems. In particular, in the absence of capacity constraints and with no restriction on the number of warehouses (with a cost of building a single warehouse) the problem appears as a special case of the 2-level facility location problem, see [1]. In the presence of capacities the problem is more similar to the capacitated facility location problem, see [2]. In case of fixed number of warehouses it also reflects properties of the k-median problem, see [3]. An insight into the theoretical complexity of the warehouse location problem, would be an excellent basis for a Master project and thesis.
References
[1] K. Aardal, F. A. Chudak, and D. B. Shmoys. A 3-approximation algorithm for the k-level uncapacitated facility location problem. Information Processing Letters, 72(5-6):161-167, 1999.
[2] V. Arya, N. Garg, R. Khandekar, A. Meyerson, K. Munagala, and V. Pandit. Local search heuristic for k-median and facility location problems. In Proceedings of STOC, pages 21–29, 2001.
[3] R. Levi, D. B. Shmoys, and C. Swamy. Lp-based approximation algorithms for capacitated facility location. In Proceedings of IPCO, pages 206-218, 2004.
Contact Person:
Semester
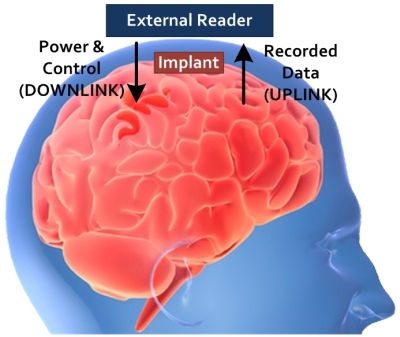
Optimization of power transfer efficiency for cortical implants
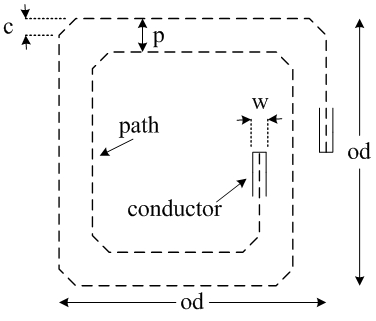
Recent studies have shown that it is possible to monitor neural activities of human brain on-site by using cortical implants. In order to avoid use of transcutaneous wiring or implanted batteries, it is desired to power up the implant and to transmit data by wireless communication. Inductive links are the most preferred method for transferring power to implantable devices. To have longer recharge time of the external battery, the power should be transferred with very high efficiency. In recent publications, it has been shown that by modifying the geometry of the inductors, the power transfer efficiency can be improved.
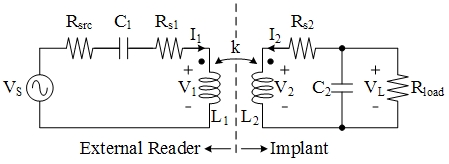 |
→ |  |
| ↓ | ||
 |
← |  |
Objectives
Implementing an algorithm to improve the power efficiency of the inductive link by modifying the geometry of the rectangular spiral inductors, given that the geometric parameters have boundary conditions and discrete values
Prerequisites
Basic knowledge in Optimization
Basic knowledge of MatLab
References
K. M. Silay, C. Dehollain, and M. Declercq, “Improvement of power efficiency of inductive links for implantable devices,” in Proc. PRIME’08 Conf., 2008, pp. 229-232.
This project is a joint study between Discrete Optimization Group in Mathematics Institute and RFIC Group in Electrical Engineering Institute.
Contact Person:
Master/Diploma/Bachelor/Semester
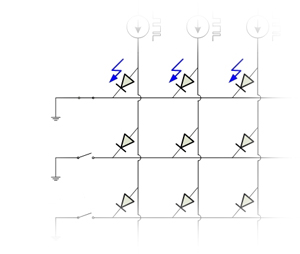
Better displays thanks to Math
Have you ever wondered why your mobile has low batteries again though you have only send text messages?
Well, one reason could be the power consumption of the display.
But this wasn’t the case with my last phone?
Since the resolutions of modern displays increases, so their power consumption does.
What has this to do with math?
A lot, since suitable decompositions of the displayed images yield significant reductions of the required electrical currents, hence lower power consumption and longer lifetime.
 |
→ | 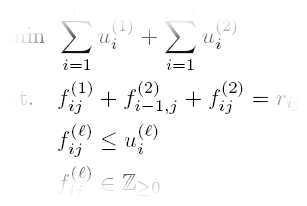 |
| ↓ | ||
 |
← |  |
Objectives
Gather an insight how flat panel displays work
See how mathematical concepts are applied to improve them
Develop basic tools to tackle the challenge
Prerequisites
Basic knowledge in Optimization
Basic knowledge of C++
Still interested? Ask me for more information by e-mail (not binding and free of charge)
Contact Person:
Semester
Single Sink with non-simultaneous demands
In the single sink problem with non-simultaneous demands, we are given an undirected network G(V,E) with cost function c: E → R+, a root node r ∈ V, and k disjoint sets of terminal nodes R1, …, Rk with Ri ⊆ V\{r}, for i=1,…,k. Each terminal node in Ri has a unit demand that wishes to send to the root node r. Still, if nodes belong to different sets, then the demands are not simultaneous among them.
The aim is to install integral min-cost capacity xe on each edge e of the network, such that, for all i=1,…,k, the installed capacity allows for routing the demands from the nodes in Ri to r.
Since we are dealing with a single sink, we can rely on the max-flow/min-cut property and write a cut-formulation for the problem, as follows. For each subset of nodes S ⊆ V, we let f(S) = maxi=1,…,k |S ∩ Ri| if r∉S, f(S) = 0 otherwise. Moreover, let δ(S) be the set of edges with exactly one endpoint in S.
A cut-formulation of the problem is:
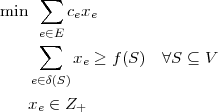
The above problem is a generalization of the Steiner Tree problem (think why!). It is known that for the Steiner Tree problem the integrality gap of this formulation is at most 2 [GW95] (in fact, the bound is tight), and that the following property holds [Jai98]:
for each extreme point of the polyhedron described by the constraints of the LP-relaxation of the above integer program, there is at least one variable xe ≥ 1/2.
We are interesting in bounding the integrality gap for the single sink problem with non-simultaneous demands, and in finding an example (if any!) where the above-mentioned property does not hold.
Objective
Implement an algorithm for computing the integrality gap of the above formulation on small instances, checking whether the optimal solution of the LP-relaxation satisfies xe ≥ 1/2 for at least one e∈E.
References
[Jai98] Kamal Jain. A factor 2 approximation algorithm for the generalized Steiner network problem, in Proceedings of the 39th Annual Symposium on Foundations of Computer Science (FOCS 1998), pp. 448–457, 1998.
[GW95] Michel X. Goemans and David P. Williamson. A general approximation technique for constrained forest prob- lems, SIAM Journal on Computing 24(2):296–317, April 1995.
Contact Person:
Master/Bachelor/Semester
Algorithms for planar graphs
Planar graphs are an important class of graphs. Due to their special structure, they admit algorithms that run faster than for general graphs. Even problems that are NP-complete in general can be solved in polynomial time when restricted to planar graphs.
The purpose of this project is to create an algorithms library for planar graphs. It shall include
Recognition
Embedding
Shortest Path
Maximum Flow
Disjoint Path
Multiflow
The algorithms shall be certifying. Furthermore, their running time shall be evaluated exper- imentally and compared with the theoretical bounds.
Contact Person:
Weight functions for routing protocols in telecommunication networks
Semester/Master
Traffic demands in telecommunication networks are routed according to some fixed routing protocols. Popular protocols, such as OSPF or IS-IS, route traffic on shortest paths according to configurable link weights. One crucial issue for network operators, is to configure link weights that realize a set of pre-defined paths. This project is devoted to find weight functions which ensure a pre-defined routing, minimizing the maximum assigned weight.
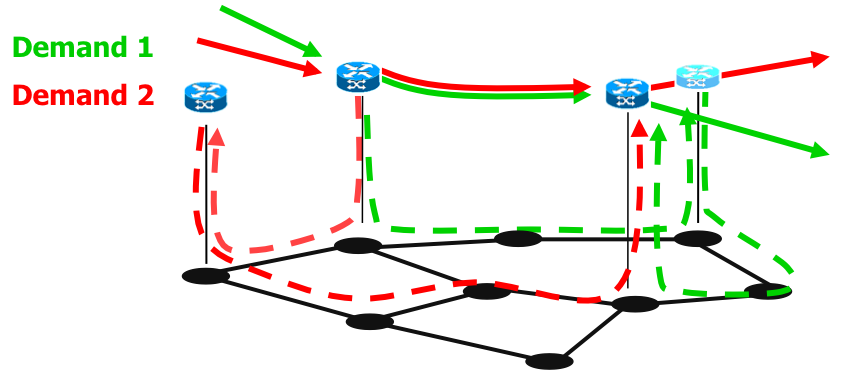
Contact Person:
Periodic Packet Scheduling on a line
Semester/Master
In this project we look at periodic packet scheduling on a line. Here is the setup, in which all parameters are assumed to be integral. We have a number of jobs, each with a start point and end point on the line. Each job has a fixed period T; every T seconds it releases a packet which travels at unit speed from its start to its end. Despite the fixed periods, suppose our flexibility is that we can choose the offsets. How hard is it to find offsets so that no two packets ever collide? If it is not schedulable, how can we find a “best” subset of tasks which is schedulable? Since these problems are computationally hard in general, what if we restrict ourselves to the important special case of “harmonic” periods where for every two periods, one divides the other?
Contact Person:
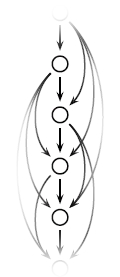
Arborescences
Semester
In a graph with a distinguished “root” vertex r, an arborescence is a tree that is directed away from r. Arborescences are known to have many nice combinatorial and algorithmic properties. This project aims to answer open questions about arborescences.
The initial plan is to investigate the following open question. Suppose we are given 4 arborescences, such that for every pair u, v of vertices, the directed edge uv appears in at most 2 of these 4. Can we always rearrange the same set of directed edges into 4 arborescences A1, B1, A2, B2, so that each Ai-Bi pair is edge-disjoint? An example is shown below. The first part of the project would be to write a computer program, e.g. in C++, to check if this holds on all small graphs.
Once work on the first question is complete we would investigate other open questions about arborescences; click here for an example.
Contact Person:
Bipartite Matching VS Non-bipartite Matching as Demand Graphs
Semester
In this project, we are given a supply graph G(V,E) that is an undirected connected graph with capacities x on the edges. A subset of vertices W ⊆ V wants to exchange demands among each others. This is represented by a demand graph D(W,F), that is an auxiliary undirected graph where an edge (u,v)∈ F means there is a unit demand between u and v to be routed on G. We say that x supports D if we can (fractionally) route all the demands on G without violating the capacity x.
Consider W to be composed by 2 disjoint subsets S = {s1,…,sk} and T = {t1,…,tk}. We are interested in the following problem:
Suppose that x supports any demand graph D that is a bipartite matching between S and T. Find the minimum α ≥ 1 such that α ⋅ x supports any demand graph D that is a (possibly non-bipartite) matching in S ∪ T.
It follows from Hu’s 2-commodity flow Theorem that, when k = 2, the minimum value for α is 1, for any G.
Objective: Implement a program to test how large α can be on some particular instances (for k ≥ 3).
Contact Person:
Polychromatic Colouring of Set Families
Semester
Consider a group of people, some pairs of which are friends. We want to arrange a multi-day phone call schedule with the following properties:
- every day, each person talks to one or more of their friends on the phone,
- nobody ever talks to the same friend more than once,
- and we want the schedule to be as long as possible (in days).
Clearly, if some person has only δ friends, the schedule could not be longer than δ days, since that person needs to talk to a distinct friend every day. So δ is an upper bound on the longest solution. However, the maximum possible schedule length might be strictly less than δ: e.g. if there are 3 people and all pairs are friends it is not hard to see the longest possible schedule is just one day, even though everyone has δ=2 friends. A theorem of Gupta from the ’70s proves that this is as bad as it gets: the maximum schedule length is always at least δ-1.
Gupta’s theorem can be stated as a polychromatic edge-colouring of a graph: for each edge (friendship) we want to assign it a colour (day) so that every vertex (person) has at least one incident edge of each colour (at least one phone call each day). We will look at variants of Gupta’s theorem for hypergraphs, meaning that instead of “friendships” of size 2, we have larger groups corresponding to hyperedges (such as committees, which would hold conference calls).
Initial goal. Use integer programming (IP) software, or other programming techniques, to compute optimal schedules on moderately large instances. This will involve trying alternative IP formulations to see what works best. (The problem is NP-complete so we don’t expect to solve all instances very quickly.)
Possible succeeding goals. (i) Use the solver to find specific instances giving better lower bounds than what is known so far, either by exhaustive enumeration, random instances, or meta-heuristics. (ii) Obtain theoretical progress: e.g. it is not known, with hyperedges of size 3, how large does δ need to be before a two-day schedule is possible.
Contact Person:
Integrality gap of the bidirected cut relaxation for Steiner tree
Master/Bachelor/Semester
For the Steiner Tree problem, one is given an undirected graph with edge costs and distinguished nodes R ⊆ V, which are called terminals. The goal is to find a tree at minimum cost, that connects all terminals.
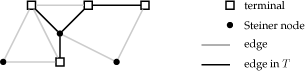
Now fix an arbitrary terminal as root r and replace each undirected edge {u,v} by the directed edges (u,v) and (v,u). Then the bidirected cut relaxation is
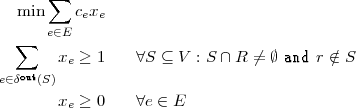
Here δout(S) denotes the set of (directed) edges, leaving S. Observe that the best integer solution to this system is the cheapest Steiner tree. We wonder, by which factor a fractional solution may be cheaper than an integer one.
Objective
Implement an algorithm to compute the integrality gap using the OR software/library of your choice (and a programming language of your choice). Recommended are C/C++ or Java. For example CPLEX, Qhull, cddlib might be useful.
Compute the integrality gap for small graphs.
A more detailed description can be found under this link.
Contact person: